TensorFlow 基礎篇〈下〉2017-08-01
前言
經過前面兩篇關於 TensorFlow 的介紹,相信大家已經對這個深度學習框架有了基本的認識。接下來,我們將會運用 TensorFlow 架構出 MNIST 手寫數字辨識的回歸模型(regression model),並利用訓練產生的模型(model)對測試資料(test data)進行預測,檢視這個方式得到的準確率(accuracy)如何。
本篇文章的內容大部份翻譯自 TensorFlow 官網 ,文章中使用的圖片也取自於相同來源。
認識 MNIST 手寫數字辨識
對於剛開始接觸 TensorFlow 、 Keras 等深度學習框架的人而言,「MNIST 手寫數字辨識」是非常適合入門的練習項目,其角色就好比剛學習程式語言時所印出的 " Hello world ! " 一樣,讓新手初步認識與練習 TensorFlow。
而 MNIST 手寫數字辨識,顧名思義,便是讓機器辨識出手寫數字影像是 0 到 9 之間的哪一個數字,究竟這種對於人類看似輕而易舉的事情,交由機器來做的表現又會如何呢?接下來,我們將會簡單介紹如何利用 TensorFlow 完成這項練習,藉此熟悉 TensorFlow 的基本運用。
MNIST 手寫數字資料集介紹
在開始實作之前,我們需要先瞭解,到底什麼是 MNIST 手寫數字資料集?
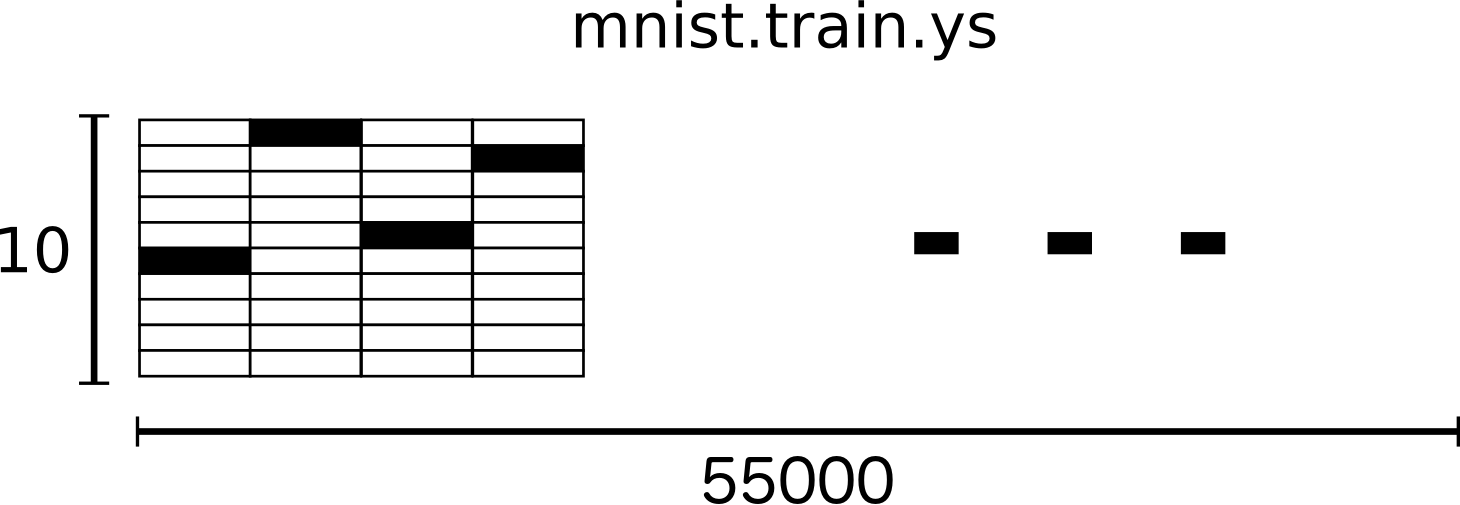
MNIST 資料集是由 Yann LeCun 等人提供在 THE MNIST DATABASE 上面的手寫數字資料,這些資料包含圖片與標籤兩種形式的內容。其中, training data(共 55000 筆)與 validation data(共 5000 筆)皆具有圖片及標籤,而 test data(共 10000 筆)則是只有圖片,而沒有標籤。每一筆資料的照片是由 28 pixels x 28 pixels ,總共 784 個 pixels 所組成,圖片顯示的是 0 到 9 之中的一個阿拉伯數字;資料的標籤則表示該手寫數字圖片所呈現的數字為何,也就是 0 到 9 中一個數值。
下面所顯示的是 MNIST 資料集中,幾張圖片經過視覺化之後的範例,我們可以由肉眼看出每張圖片所代表的數字。
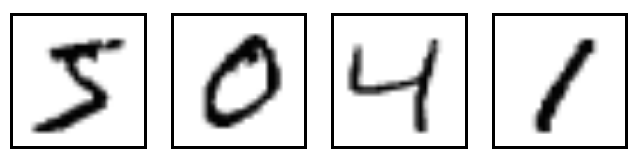
圖片資料形式與讀取
MNIST 資料集是一個適合拿來當作 TensotFlow 的練習素材,在 TensorFlow 的現有套件中,也已經有內建好的 MNIST 資料集,我們只要在安裝好 TensorFlow 的 Python 環境中執行以下程式碼,即可將 MNIST 資料成功讀取進來。
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
根據文章前段所述,每一筆 MNIST 資料的照片由 784 個 pixels 組成,因此,我們可以把它視為一個大型矩陣(array),矩陣裡每一項的資料則是代表每個 pixel 顏色深淺的數值,如下圖所示。
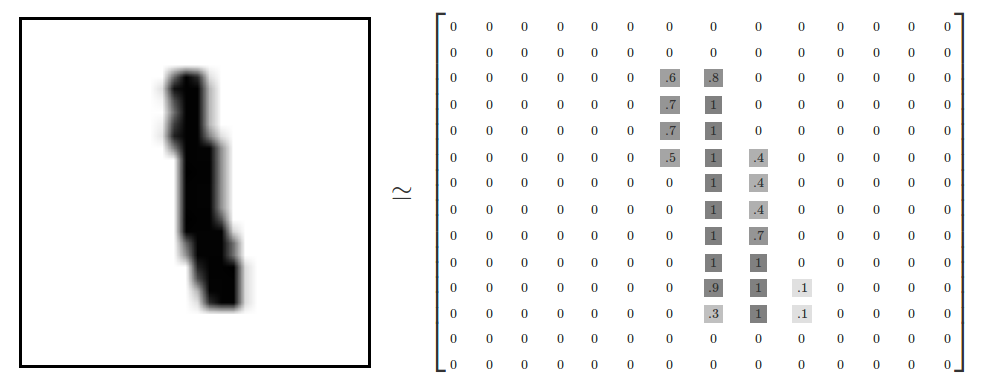
每一筆 MNIST 資料的標籤,則是以 one-hot encoding 的形式呈現,每一個標籤都是一個 one-hot vector。
所謂 one-hot vector 的形式,代表該 vector 第一個維度對應數字 0 ,第二個維度對應數字 1 ,以此類推,總共有十個維度。一個標籤數值為 n 的標籤,只有其對應之維度的數值為 1 ,其他維度的數值皆為 0 ,而如此就是 one-hot vector 的特性。
舉例來說,代表標籤數字為 0 的 one-hot vector 為 [ 1 0 0 0 0 0 0 0 0 0 ] 、代表標籤數字為 1 的則是 [ 0 1 0 0 0 0 0 0 0 0 ] ,諸如此類。將這些 one-hot vector 串聯(concatenate)起來,就會形成 one-hot array ,MNIST 資料集中的標籤資料即是用這種方式表示。
經過以上解說,我們已經大致認識 MNIST 資料集的內容,此外,以此資料集中的 training data 為例,我們可以從下面這兩張示意圖瞭解 MNIST 資料集的大致資料格式。

softmax 回歸模型介紹
前言中提到,我們要實作的是一個回歸模型,對於 MNIST 這種複數類別的資料, softmax 回歸模型是一個較為常見且基本的模型, sotfmax 模型會將輸入(input)的資訊,透過乘上權重(weight)與加上偏差(bias),再經由 softmax 函式轉換成機率的方式,得到每一種類別所代表的可能性並作為輸出(output),進而決定輸入的資訊是屬於哪一種類別。
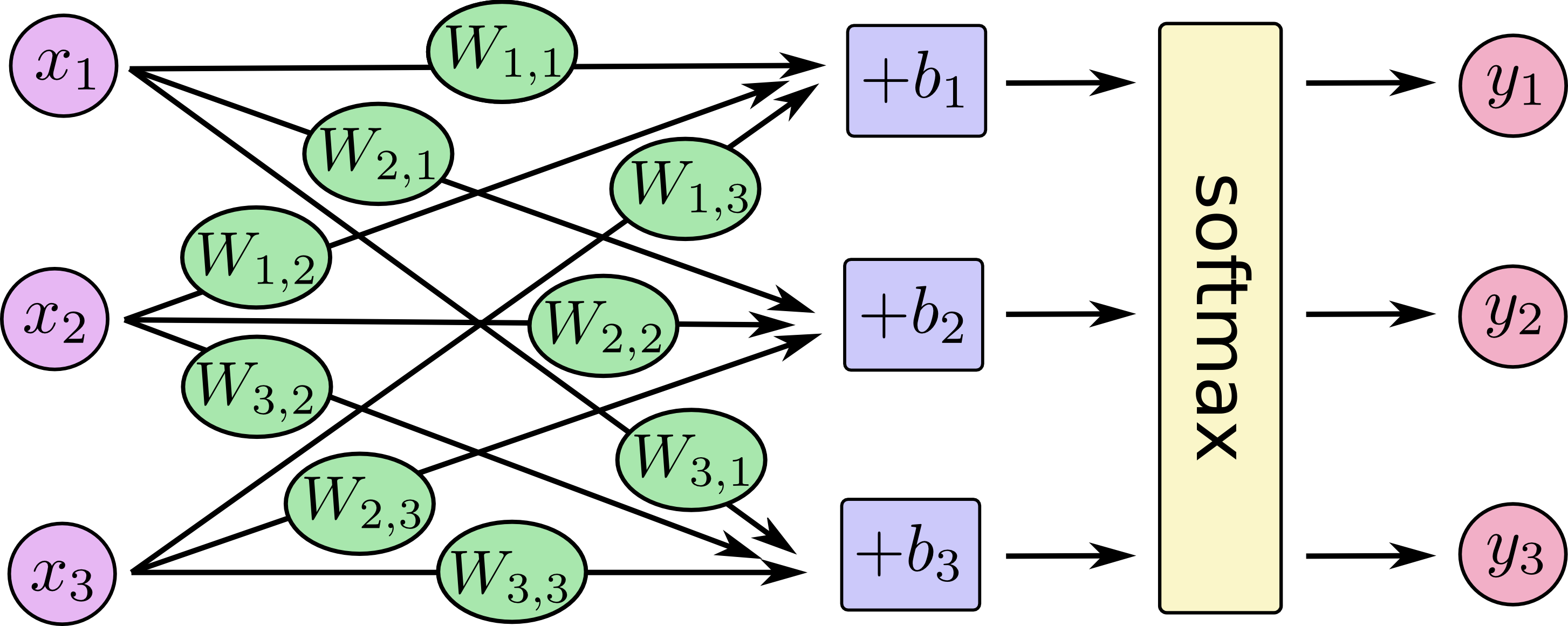
對於電腦的運算而言,我們可以把上面這張圖化作以下這個矩陣運算的形式。
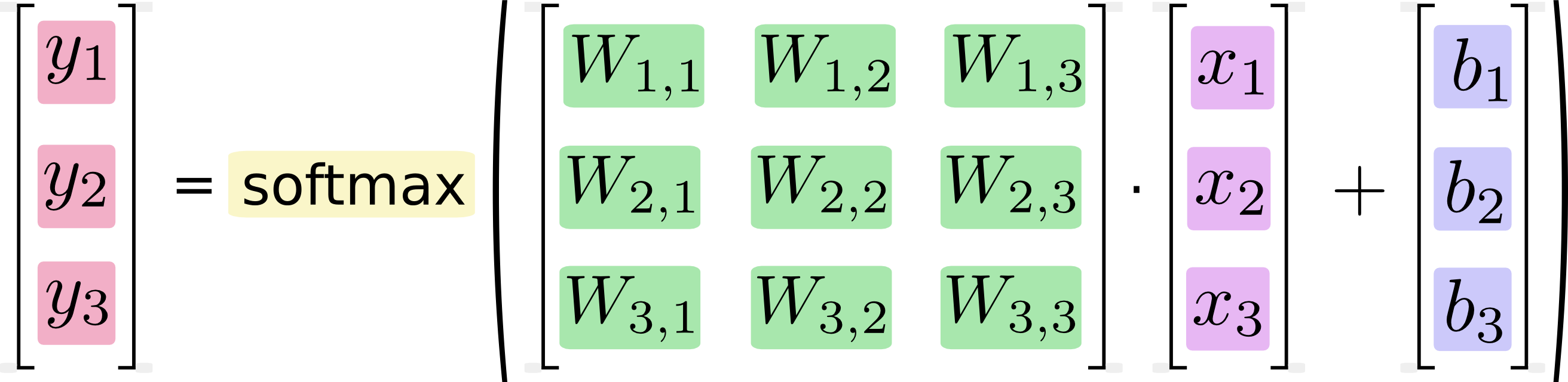
說明完 softmax 回歸模型的大致原理,接著,我們將把這些觀念轉換成程式碼吧!
softmax 回歸模型實作
首先,因為接下來許多我們需要使用功能的函式都在 TensorFlow 裡面可以找到,所以先將 TensorFlow 匯入進來。
import tensorflow as tf
然後,讓我們來創造一個代表輸入資料的佔位符號(placeholder),名稱為 x ,可以將它視作盛裝輸入資料的「容器」,並設定好它的維度資訊。因為我們要輸入的資料是維度為 784 個 pixels 的圖片,所以這個佔位符號的形狀是 [None, 784], None 可以是一個任何大小的維度,取決於輸入資料圖片數多寡。
x = tf.placeholder(tf.float32, [None, 784])
softmax 回歸模型所使用到的權重與偏差,則是分別以 W 及 b 表示,而它們是可以更改數值的張量(tensor),因此我們以 Variable 這個類別創造出所需形狀的 W 和 b ,並且先將張量的初始值全都設定為零。
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
再來我們只要使用 TensorFlow 內建的函數,將輸入資料 x 和權重 W 矩陣相乘,並加上偏差 b 後,放到 softmax 函數中,便將這個 softmax 回歸模型定義出來了。
y = tf.nn.softmax(tf.matmul(x, W) + b)
訓練模型
建構好模型的雛型之後,我們要開始訓練這個模型,讓它能夠達到我們所希望的預測能力。至於應該用什麼方式評估模型的好或壞呢?我們會以預測結果跟正確答案做比較,得到兩者的差異大小,也就是 loss ,作為判斷模型好壞的評斷依據。
TensorFlow 的套件中有一個我們經常拿來計算 loss 的函式,叫作 cross-entropy ,其較深入的細節在這篇文章中不會細談。當計算出來的 loss 愈小,就代表目前模型的預測結果愈接近正確答案,而我們的目標是讓訓練模型時算出來的 loss 逐漸下降。
為了能使用 cross-entropy 比較預測結果和正確答案,我們需要先創造一個存取正確答案的 placeholder ,名為 y_ 。
y_ = tf.placeholder(tf.float32, [None, 10])
如果要將上面 cross-entropy 的數學式實作出來,可以參考下面這段程式碼。
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
不過,直接用這種方式實作 cross-entropy ,因為數值計算上會不夠精確與穩定,所以通常我們會使用 tf.nn.softmax_cross_entropy_with_logits 取代前面提到的方法,並透過 backpropagation 演算法,追蹤 W 、 b 這些變數跟 loss 之間的關聯。
我們可以藉由 Optimizer 來計算 loss 的梯度(gradient)。在這裡以許多 Optimizers 其中之一的 GradientDescentOptimizer 為例,關於 Gradient Descent 的原理,可以參考維基百科的資料。
learning_rate = 0.05
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy)
當 Graph 的內容都已經設定完成之後,接著就可以將 TensorFlow 的運算指定給 Session 了。
sess = tf.Session()
一開始,要先將 Variables 初始化。
tf.global_variables_initializer().run()
如果我們要讓訓練過程跑 1000 次,每次取 100 筆資料進行訓練,只要按照下面這段程式碼所寫的去執行即可。
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
評估模型
在實際執行程式之前,我們還需要一些程式碼來評估,最後訓練出來的模型,拿來預測 test data 的準確率如何。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
最後,我們開始執行整個 Session ,並顯示出以訓練完的模型預測 test data 的準確率。
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
根據 TensorFlow 官網所寫,利用這一篇所使用的方法,可以得到大約 92 % 的準確率。
就筆者查到的資料,目前(西元 2017 年 7 月)準確率最高的方法是由 Li Wan 等人在西元 2013 年所提出,利用各種 deep learning 的技巧,達到了高達 99.79 % 的準確率!如果想要瞭解關於這個方法的詳細內容,請參考這個連結。
結語
到此為止, TensorFlow 基礎篇的教學終於告一段落了!
總結來說, TensorFlow 是一個廣受歡迎的深度學習框架,和其他套件相比,它在自由度相對比較高。此外,又因為是由 Google Brain 所開發,以及有廣大的使用社群,縱使使用者在操作上遇到問題,也能從網路上找到許多可以參考的資源。



沒有留言:
張貼留言